
 MENU
MENU 

New quick-learning neural network powered by memristors
U-M researchers created a reservoir computing system that reduces training time and improves capacity of similar neural networks.

 Enlarge
EnlargeA new type of neural network made with memristors can dramatically improve the efficiency of teaching machines to think like humans. The network, called a reservoir computing system, could predict words before they are said during conversation, and help predict future outcomes based on the present.
The research team that created the reservoir computing system, led by Wei Lu, U-M professor of electrical engineering and computer science, recently published their work in Nature Communications.
Reservoir computing systems, which improve on a typical neural network’s capacity and reduce the required training time, have been created in the past with larger optical components. However, the U-M group created their system using memristors, which require less space and can be integrated more easily into existing silicon-based electronics.
Memristors are a special type of resistive device that can both perform logic and store data. This contrasts with typical computer systems, where processors perform logic separate from memory modules. In this study, Lu’s team used a special memristor that memorizes events only in the near history.
Inspired by brains, neural networks are composed of neurons, or nodes, and synapses, the connections between nodes.
A lot of times, it takes days or months to train a network. It is very expensive.
Wei Lu
To train a neural network for a task, a neural network takes in a large set of questions and the answers to those questions. In this process of what’s called supervised learning, the connections between nodes are weighted more heavily or lightly to minimize the amount of error in achieving the correct answer.
Once trained, a neural network can then be tested without knowing the answer. For example, a system can process a new photo and correctly identify a human face, because it has learned the features of human faces from other photos in its training set.
“A lot of times, it takes days or months to train a network,” says Lu. “It is very expensive.”
Image recognition is also a relatively simple problem, as it doesn’t require any information apart from a static image. More complex tasks, such as speech recognition, can depend highly on context and require neural networks to have knowledge of what has just occurred, or what has just been said.
“When transcribing speech to text or translating languages, a word’s meaning and even pronunciation will differ depending on the previous syllables,” says Lu.
This requires a recurrent neural network, which incorporates loops within the network that give the network a memory effect. However, training these recurrent neural networks is especially expensive, Lu says.
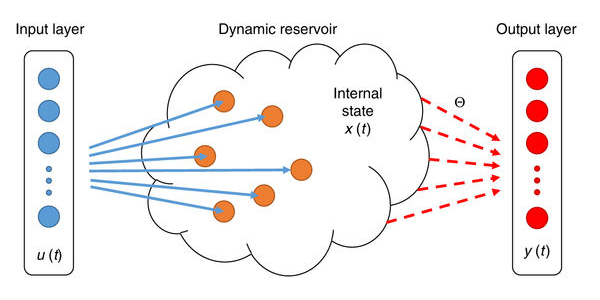
Reservoir computing systems built with memristors, however, can skip most of the expensive training process and still provide the network the capability to remember. This is because the most critical component of the system – the reservoir – does not require training.
When a set of data is inputted into the reservoir, the reservoir identifies important time-related features of the data, and hands it off in a simpler format to a second network. This second network then only needs training like simpler neural networks, changing weights of the features and outputs that the first network passed on until it achieves an acceptable level of error.
 Enlarge
Enlarge“The beauty of reservoir computing is that while we design it, we don’t have to train it,” says Lu.
The team proved the reservoir computing concept using a test of handwriting recognition, a common benchmark among neural networks. Numerals were broken up into rows of pixels, and fed into the computer with voltages like Morse code, with zero volts for a dark pixel and a little over one volt for a white pixel.
Using only 88 memristors as nodes to identify handwritten versions of numerals, compared to a conventional network that would require thousands of nodes for the task, the reservoir achieved 91% accuracy.
INFOBAND
Reservoir computing systems are especially adept at handling data that varies with time, like a stream of data or words, or a function depending on past results.
To demonstrate this, the team tested a complex function that depended on multiple past results, which is common in engineering fields. The reservoir computing system was able to model the complex function with minimal error.
Lu plans on exploring two future paths with this research: speech recognition and predictive analysis.
“We can make predictions on natural spoken language, so you don’t even have to say the full word,” explains Lu.
“We could actually predict what you plan to say next.”
In predictive analysis, Lu hopes to use the system to take in signals with noise, like static from far-off radio stations, and produce a cleaner stream of data. “It could also predict and generate an output signal even if the input stopped,” he says.
 Enlarge
EnlargeThe work was published in Nature Communications in the article, “Reservoir computing using dynamic memristors for temporal information processing”, with authors Chao Du, Fuxi Cai, Mohammed Zidan, Wen Ma, Seung Hwan Lee, and Prof. Wei Lu.
The research is part of a $6.9 million DARPA project, called “Sparse Adaptive Local Learning for Sensing and Analytics,” that aims to build a computer chip based on self-organizing, adaptive neural networks. The memristor networks are fabricated at Michigan’s Lurie Nanofabrication Facility.
Lu and his team previously used memristors in implementing “sparse coding,” which used a 32-by-32 array of memristors to efficiently analyze and recreate images.
In the Media
Crossbar pushes resisted RAM into embedded AI
The company, co-founded by Wei Lu, EECS professor, hopes to move artificial intelligence systems into mobile devices.
What’s Next In Neuromorphic Computing
Wei Lu, EECS professor, has his work mentioned in a discussion of how the commercialization of neuromorphic computing will require improved devices and architectures in Semiconductor Engineering.